
Introduction
The Transformer architecture revolutionized the approach to processing sequences of data such as text, audio, or time signals. It was created as an alternative to earlier recurrent networks (RNNs) and focused on parallel processing of sequence elements. For the programmer, this means fewer intricate mechanisms related to hidden state propagation and significantly shorter training times, especially for very long inputs.
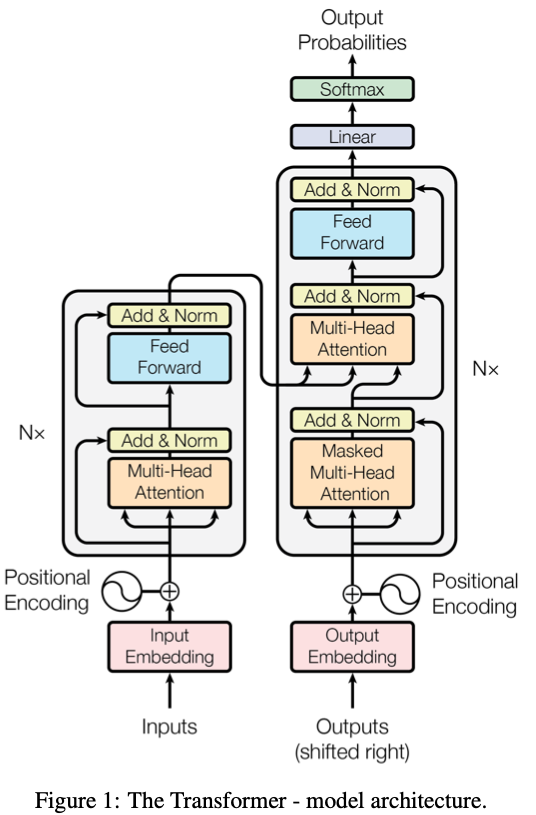
Transformers network, source https://arxiv.org/pdf/1706.03762
A brief description of how it works
A transformer is based on an attention mechanism that determines for each element of a sequence how important the other input elements are in the context of the current position. Instead of processing the data step by step, the model analyzes all positions simultaneously, assigning each “query-key-value” pair its weight based on contextual dependencies. This allows the network to find relationships between words or pieces of data, even if they are separated by hundreds or thousands of positions.
Main benefits
Transformers give the programmer the ability to scale the computations practically infinitely, as long as there is enough GPU/TPU budget. The parallelism in the computations translates into much faster training than in the case of RNNs, and the lack of sequential processing eliminates gradient decay problems. The model manages contexts at the multi-head attention level, which allows capturing diverse relationships in the data without manual feature engineering.
Why it’s groundbreaking
The breakthrough of Transformers is related to two key aspects. First, universality: the same architecture works well in machine translation, natural language understanding, code generation, or image analysis. Second, scalability: as the number of parameters and layers increases, the model’s capabilities increase, which has been confirmed by experiments with large language models such as GPT or BERT. In practice, this means that the development of hardware infrastructure directly affects the improvement of model results.
Practical applications
In the development environment, Transformer often appears as the foundation of tools supporting writing code, automating unit tests, or generating documentation. In recommendation systems, it allows for better matching of the offer to the user, analyzing their previous interactions as a sequence of events. In natural language processing, it facilitates the implementation of chatbots and voice assistants with much higher response quality.
Integration with existing stack
For a programmer, implementing a Transformer model can be divided into stages: data preparation (tokenization and dictionary construction), selection of an appropriate implementation (frameworks such as TensorFlow, PyTorch or ready-made Hugging Face libraries), fine-tuning on your own data set and performance optimization during production implementation. Thanks to the modular structure, you can freely configure the number of layers, width of attention heads or regularization strategies without having to change the entire network logic.
Summary
Transformers have revolutionized the way computers learn from data sequences. Their advantage lies in the parallelism of calculations, configuration flexibility and the ability to capture long-distance dependencies without excessive engineering. For a programmer, they open the door to creating more advanced, scalable and efficient applications based on artificial intelligence, from text automation to advanced recommendation systems. Transformers are today the foundation of modern machine learning, which in practice translates into faster implementation times and better results in real tasks.