
Technological construction in the project “Tool supporting project management, implementations, and customer service using NLP/NLU algorithms and speech recognition”
Main objective and research problem
The main objective of the project is to develop an innovative system supporting and automating project management processes using artificial intelligence algorithms based on natural language analysis methods.
The main research problem is to develop a set of algorithms and methods for analyzing the content of messages in Polish related to the project management domain, which will enable automation of key processes related to project management, implementation, and service support.
System architecture
The project uses a distributed architecture based on microservices, which will allow for the independence of individual modules and enable easy system development in the future without interfering with existing modules. The main elements of the architecture include:
- Microservice architecture – each functional module is a separate service
- Data bus – ensuring communication between modules
- API interfaces – for intra-system communication and integration with external systems
- Client applications – web and mobile, designed to be intuitive, responsive, and adapted to various devices
Project management system architecture with NLP/NLU – detailed description of tools
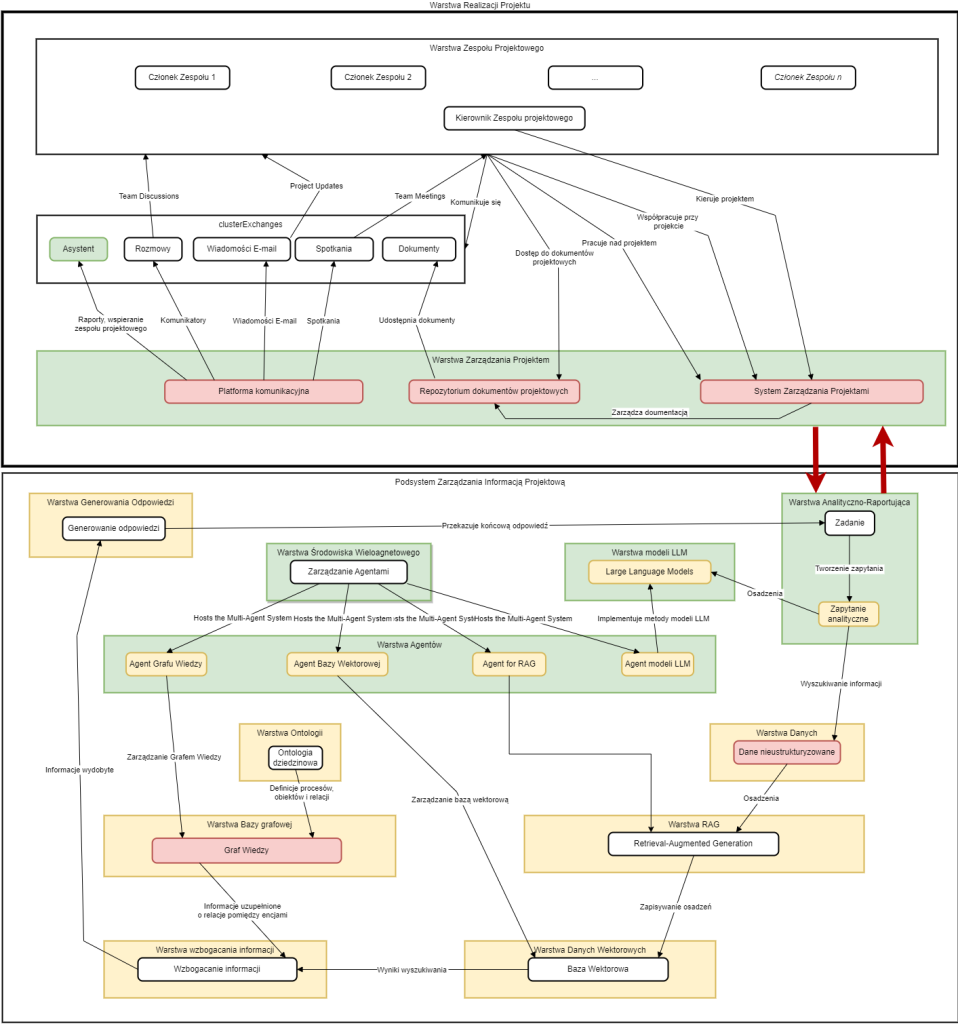
Project implementation layer
The project management system uses communication and team collaboration tools. Team communication systems such as Microsoft Teams and Slack are used to effectively conduct discussions and organize team meetings, ensuring continuous exchange of information between project team members. Tracking progress and updates in projects is possible thanks to dedicated project management tools, including JIRA, Asana and Trello. Complete project documentation is stored and shared using specialized documentation systems, mainly Confluence and SharePoint, which allows central access to all important project materials and streamlines the team collaboration process.
Project implementation layer
The system uses a range of tools for comprehensive data capture from various sources. The virtual assistant is a key element of the system and is based on a voice interface using ASR (Automatic Speech Recognition) technology, implemented using Mozilla DeepSpeech or Whisper solutions, which have been adapted to the specifics of the Polish language. Email connectors based on API interfaces for Gmail and Microsoft Exchange services are used for automatic retrieval and analysis of electronic messages. Recording and transcription of team meetings are carried out through dedicated, proprietary solutions built on PyAudio and librosa libraries, which enable effective sound capture and processing. For digitizing paper documents, document scanning systems using OCR technology, implemented with Tesseract or ABBYY FineReader tools, have been deployed, ensuring high accuracy of text recognition. The whole is complemented by data anonymization procedures, which are based on proprietary algorithms for masking personal data, designed in accordance with GDPR requirements, which guarantees full protection of sensitive information in the system.
Project management layer
The project management system has implemented integration platforms that ensure the coherent functioning of all components. The communication platform is based on a microservice architecture, using Spring Boot or Django technologies, and is supported by an efficient message queuing system, such as RabbitMQ or Kafka, which ensures reliable information exchange between system components. For efficient storage of project documentation, a document repository has been implemented, which can be realized as a distributed file system (HDFS) or specialized document databases, such as MongoDB or Elasticsearch, depending on the specific project requirements. The central element of the entire solution is the Project Management System, which has been designed as a proprietary solution based on a modern RESTful API, providing flexible integration with popular external tools through dedicated programming interfaces, such as JIRA API.
Project information management subsystem
LLM Models Layer
The system uses natural language processing technologies that have been carefully selected to meet the project requirements. In terms of language models, both fine-tuned versions of popular Gemma3 models and proprietary LLM models built on the transformer architecture, especially XLM-RoBERTa, have been applied, which have been specially adapted to work effectively with the Polish language. The implementation of NLP functionality is based on recognized libraries, such as HuggingFace Transformers and SpaCy, with the latter using Polish language models, in particular pl_core_news_lg, ensuring high quality text analysis in Polish. The process of adapting the models to the specific needs of the project management domain is realized using fine-tuning tools, among which PyTorch Lightning plays a key role, enabling efficient and optimized fine-tuning of models on specialized datasets related to project management.
Multi-agent environment layer
The system uses solutions in the field of agent architecture that create a coherent platform for AI process coordination. LangGraph was used as the basic agent framework, which was chosen due to its greater extensibility compared to alternative solutions, such as LangChain, which enables more flexible adaptation to project requirements. Integration with the existing microservice infrastructure is realized through specially designed, custom LangGraph extensions that ensure seamless communication through standard REST and gRPC interfaces. To optimize data processing performance, an orchestration system based on Ray has been implemented, which enables efficient parallel processing of tasks and is natively supported by LangGraph, eliminating the need to implement additional integration layers.
Agent layer
The system has implemented an agent architecture, which is a key element of the entire solution. Agents have been defined as LangGraph components with attached custom tools, which allows for precise customization of their functionality to the specific requirements of the project. Communication and coordination between individual agents takes place through shared contextual memory, implemented using the LangGraph State Manager mechanism, which enables efficient sharing of information and maintaining consistency throughout the processing process. To ensure flexible integration with external systems and databases, such as Neo4j, Pinecone, and others, special adapters implemented as LangGraph tools have been developed, which standardize communication and simplify the process of data exchange between agents and external infrastructure.
Ontology layer
The system has implemented ontology management mechanisms that provide a structural representation of domain knowledge. Protégé, a renowned ontology editor, is used to create and manage the domain ontology, offering an intuitive interface for modeling complex knowledge structures in the field of project management. Ontology representation is based on recognized standards, such as OWL (Web Ontology Language) and RDF (Resource Description Framework), which provide a formal structure and interoperability of knowledge in the system. To ensure the possibility of automatic inference based on the collected knowledge, the system uses advanced inference engines, such as Apache Jena or OWLReady2, which perform logical inference operations on the ontology, enabling the extraction of hidden relationships and the generation of new knowledge based on existing facts.
Graph database layer
The system uses Neo4j as the main database for storing knowledge graphs, which allows for effective representation of complex relationships between project entities. The Cypher query language is used for searching and analyzing relationships in the knowledge graph, which enables precise formulation of queries and efficient searching of graph structures. Visualization of relationships recorded in the knowledge graph is realized by Neo4j Bloom or D3.js libraries, which transform abstract data structures into readable graphical representations, facilitating understanding of the relationships between project elements.
Vector Data Layer
The system uses Weaviate or Qdrant as vector databases for indexing and searching vector representations of project documents. The SentenceTransformers library, along with multilingual models, is used to generate embeddings for texts in Polish, which transform text documents into vector representations that preserve semantic meaning. Analysis and visualization of the multidimensional vector space are enabled by dimensionality reduction algorithms, such as UMAP and t-SNE, which allow for the transformation of complex vector structures into a form that enables their visual interpretation by system users.
RAG Layer
The system has implemented a RAG (Retrieval-Augmented Generation) layer as a proprietary solution based on a modular architecture, which enables flexible adaptation of components to the specific needs of the project. Information retrieval is realized through hybrid methods that combine the BM25 algorithm with cosine similarity measure, providing higher effectiveness in finding relevant documents than each of these methods used separately. Context processing in the system uses techniques such as sliding window chunking for document segmentation, reranking of search results to select the most appropriate fragments, and dynamic context compression, which optimizes the amount of information passed to the language model.
Response Generation Layer
The system uses a response generation layer based on fine-tuned Bloom or Phi-3 models, which have been specially adapted to the specifics of the project management domain. Quality control of generated answers is realized by an ensemble learning mechanism, which uses multiple models simultaneously to verify the consistency and compliance of created content. In order to minimize the phenomenon of hallucination, i.e., generating false information, the system uses fact verification methods, which verify the generated content by comparing it with facts recorded in the knowledge base and ontological structures. .
Analytical and Reporting Layer
The system includes an analytical-reporting layer using Business Intelligence tools, such as PowerBI and Tableau, which have been integrated with the system’s API, enabling dynamic visualization of project data. For report generation, JasperReports engines or a proprietary solution implemented in React.js are used, which transform project data into readable documents adapted to user needs. A dedicated module using algorithms based on both predefined rules and machine learning techniques implemented using the Scikit-learn library performs detection of potential problems in projects.
Infrastructure Layer
The system has applied an infrastructure layer based on many complementary solutions. Container orchestration is realized by Kubernetes, which manages microservices and ensures their scalability and reliability. Continuous integration and deployment processes are handled by the CI/CD system, using GitLab CI or GitHub Actions, which enables automatic testing and deployment of new software versions. System operation monitoring and log centralization are provided by a set of tools including Prometheus for collecting metrics, Grafana for their visualization, and ELK Stack (Elasticsearch, Logstash, Kibana) for comprehensive log analysis. System security is based on OAuth 2.0 and JWT mechanisms used for user authentication and authorization, as well as regular penetration tests verifying the system’s resistance to potential attacks.
User interfaces
The system’s web interface was built using the React.js library along with Material-UI components, which ensures a consistent look and functionality for both administrators and regular users. Mobile access to the system is enabled by an application created in React Native or Flutter technology, which offers key system functionalities on mobile devices. Traditional interfaces are complemented by a conversational interface in the form of a proprietary chatbot solution, which has been integrated with a voice assistant, allowing users to interact with the system using natural language.
The system as a whole implements an event-driven architecture, where communication between components takes place through message brokers (Kafka), which ensures scalability and fault tolerance. Key aspects of integration include standardized RESTful APIs for communication between services and Circuit Breaker mechanisms (e.g., Resilience4j) for ensuring error resilience.
AI Technologies and Tools
The system uses advanced AI technologies integrated into a coherent microservice architecture:
Large Language Models (LLM) integrated with knowledge bases and domain knowledge
The system uses large language models integrated with domain knowledge bases. The basic LLM models in the system are GPT-4 and Gemma 3, available through OpenAI API or Ollama API programming interfaces. For tasks specific to the Polish language, the system uses specialized models, such as the HerBERT platform, which is a Polish implementation of the BERT architecture, and the plT5 model adapted for processing Polish texts. Adaptation of these models to the specific domain of project management is realized through fine-tuning mechanisms using DeepSpeed and PEFT (Parameter-Efficient Fine-Tuning) libraries, which allow for efficient tuning of model parameters with limited computational resources. Integration of models with knowledge bases is provided by Langchain DocumentLoaders and TextSplitters components, which enable processing and segmentation of project documentation into a format suitable for language models. The system also uses context optimization techniques, including auto-merging retrieval, which dynamically adjusts the length of the context passed to the model depending on the complexity of the query and available resources.
RAG (Retrieval-Augmented Generation) methods for adding semantic context
The system uses RAG (Retrieval-Augmented Generation) methods for adding semantic context. The basic RAG infrastructure is LlamaIndex, which offers a coherent ecosystem of tools for working with documents and language models. Document indexing is realized by the LlamaIndex ServiceContext component with embedder configuration specially adapted for the Polish language. The system uses search strategies in the form of LlamaIndex Hybrid Search, which combines the BM25 algorithm with semantic search, allowing for precise finding of relevant document fragments. Conversation context tracking is provided by LlamaIndex’s TextCorpus and ConversationalRetrievalChain components, which store interaction history and take it into account in subsequent responses. Filtering and ordering of search results takes place using LlamaIndex’s node postprocessors along with CustomFilters, which have been adapted to specific project needs. Context enrichment is realized by MetadataReplacementPostProcessor, which dynamically supplements the context with additional project metadata, increasing the relevance of generated responses.
Knowledge graphs allowing for the creation of structured representations of entities and relationships.
The system uses knowledge graphs to create ordered representations of entities and relations. Neo4j was used as a graph database along with the Graph Data Science Library, which enables algorithmic analyses on graph structures. Graph structure modeling takes place using the Neo4j Arrows tool, which allows for visual design of the knowledge graph model and facilitates understanding of complex relationships. Ontology management is realized through Neo4j SHACL, used for defining and validating data schemas in the graph. The interface to the graph is provided by the Neosemantics (n10s) component, which enables integration of RDF and OWL standards with the Neo4j database. Queries to the graph are executed using the Cypher language and the LlamaIndex’s Neo4jIndex component, which allows for semantic searching of the graph structure. Graph generation in the system is aided by Llama Index EntityExtractor, which automatically recognizes entities and relationships in the text, transforming unstructured data into ordered graph structures.
NLP/NLU algorithms for extracting information from textual data
The system uses NLP/NLU algorithms for efficiently extracting information from textual data. Basic text processing is realized by the SpaCy library using the pl_core_news_lg model adapted to the specifics of the Polish language. Entity recognition (Named Entity Recognition) is based on SpaCy mechanisms with models adapted to the project domain, which enables identification of key elements in documents. Extraction of relationships between entities takes place using LlamaIndex’s Relation Extraction, which has been modified for better handling of Polish language structures. Text categorization in the system is based on the Transformers library with the DistilBERT model, which has been fine-tuned on project data. Sentiment analysis realized by the HerBERT model with a dedicated classification module is used to detect potential project problems. Keyword extraction uses the KeyBERT tool along with Polish embeddings, which enables automatic tagging of documents. Processing of legal documents is conducted using Docusaurus tools and a custom entity extractor, specially designed for project documentation.
ASR (automatic speech recognition) technologies for processing voice data
The system uses an ASR engine based on the Wav2Vec2-XLS-R-300M model, which has been adapted to the specifics of the Polish language and functions under the designation wav2vec2-xls-r-300m-pl-cv8. Preparation of audio data is realized using Librosa and PyDub libraries, which enable processing and analysis of audio signals. Real-time speech transcription uses WebRTC and Socket.io technologies, which ensure efficient transmission of audio streams between system components. Recognition of individual speakers during project meetings is realized by the pyannote.audio library, which performs speech diarization and assigns statements to specific people. Normalization of transcribed text takes place using custom rules adapted to the Polish language, implemented using the spaCy library. Detection of user intentions in voice statements is provided by the Rasa NLU framework with a set of intentions adapted to the project management domain. Text-to-speech conversion is realized by the FastSpeech 2 model working with Polish voice models, which allows for the generation of naturally sounding voice messages.
Multi-agent environments with specialized agents
The system uses a multi-agent environment consisting of specialized agents responsible for various tasks. The main coordinator of activities in this environment is an orchestration framework based on LangChain Agent Supervisor architecture, which manages workflow and task allocation. Communication between individual agents is facilitated by the LangChain AgentExecutor protocol with the MessageHistory component, which ensures a coherent flow of information and maintenance of conversation context. The system includes six types of specialized agents. The Knowledge Graph Agent is based on LangChain Neo4jToolkit with a set of customized Cypher tools, enabling operations on the graph database. The Vector Database Agent uses LangChain VectorStoreToolkit configured for the Qdrant database, which allows for effective semantic search. The RAG Agent functions based on LangChain RetrievalQA with chain_type=”refine” configuration, enabling gradual refinement of answers. The LLM Agent uses LangChain LLMChain along with configurable prompt templates adapted to the project context. The Task Agent is based on the LangChain PlanAndExecute component with direct access to the project management system API, which enables planning and execution of specific project tasks. The Forms Agent uses LangChain TextMapReduceChain for automatic completion of project forms based on available data and context.
Integration of all AI components
The system has applied several elements ensuring the coherence of AI component integration. The abstraction layer is LangChain Tools, which acts as a universal API for all AI components, providing a uniform access interface. Monitoring and logging of agent activities is realized by an orchestration mechanism based on LangChain callbacks, which records the course of processes and enables their analysis. Long-term memory implemented as LangChain’s ConversationSummaryMemory serves for building and storing project history, creating condensed summaries of previous interactions. The central element of integration is a coordinating server based on FastAPI, providing endpoints for all AI functionalities and managing data flow in the system. Asynchronous communication between components is provided by the Kafka event bus, which enables independent operation of individual system elements. Tracking the performance of language models is realized by the Weights & Biases tool, which collects metrics and enables optimization of system operation. Fast access to similar contexts is provided by Redis Vector Search, acting as a vector cache, which accelerates the search for semantically similar information.
Security and management
The system uses a number of tools ensuring security and proper management of AI models. Access control to AI functionalities is realized by Langfuse, which manages user permissions and monitors resource usage. Model versioning takes place using MLflow, which tracks versions, parameters, and results of individual models in the production environment. Monitoring of input data quality is provided by the Evidently tool, which detects data drift and alerts to potential data quality problems. Sanitization and validation of prompts is realized by PromptArmor, which protects the system against attacks through prompt manipulation. The RAGAS tool is used for automatic evaluation of responses generated by RAG mechanisms, which measures the quality and relevance of generated content. Presidio from Microsoft ensures identification and masking of confidential data in documents, which recognizes and secures sensitive information, such as personal or financial data.
Databases and data management
The system has applied various types of databases, which are used to store and process specific types of data. A relational database is used to store project structures, ensuring efficient management of information about projects, tasks, and users. Ontologies and knowledge bases describe the integration of textual and voice data with project processes, which allows for semantic linking of different types of information. A special database stores recordings of sound samples from conversations, email correspondence, and documentation, which enables analysis of project communication. The system also implements methods and procedures for data anonymization, which protect the privacy and personal data of project participants. Vector databases serve as a repository of embedded representations of documents, enabling semantic search and comparison of content. The whole is complemented by a knowledge graph management system, which stores and visualizes relationships between project objects, supporting complex queries and analyses.
Functional components of the system
The system consists of the following modules:
- Data acquisition module:
- Connectors to multiple sources (email, communicators, project documentation, paper
- Data processing and preliminary analysis algorithms
- Collection of documents of various origins related to the project management domain
- NLP/NLU module:
- Algorithms based on text understanding methods performing text categorization
- Algorithms for feature and parameter extraction from documents and conversations
- Module enabling the conversion of speech signal to text and its semantic analysis
- Methods for fine-tuning machine learning models
- Voice assistant module:
- ASR techniques for interaction and communication with project participants
- User intention detection algorithms
- Functions for automatic generation of suggestions, hints, and recommendations based on context analysis
- Integration with the knowledge base to obtain information about projects and responsible persons
- Analytical module:
- Algorithms for identifying threats and suggesting appropriate actions
- Systems for generating reports and analyses related to project implementation
- Project data visualization tools
- Project management module:
- Mechanism for automatic completion of project forms
- System for automation of project management processes
- Tools for designing forms for different types of projects
- Mechanisms for task assignment and decision process support
User interfaces
The system is available via:
- Web application – interface accessible from a browser
- Mobile application – for access from mobile devices
- Voice interface – voice assistant enabling natural interactions with the system
Integrations with external systems
The system integrates with:
- Project and task management systems (e.g., Jira, MS Azure DevOps)
- Version control tools (e.g., Git)
- Calendars and scheduling systems
- Communication systems (email, communicators)
- Documentation systems
Communication protocols and standards
The project uses the following protocols and standards:
- REST API for communication between modules and external systems
- WebSocket for real-time communication
- JSON/XML for data exchange
- OAuth/JWT for authorization and authentication
- HTTPS for secure communication
Security aspects
The project includes ensuring data integrity and security. The system ensures:
- Data anonymization methods
- Resistance to database attack methods
- Encryption of data at rest and during transmission
- Access control and authorization systems
- Security monitoring and auditing
Technologies supporting development
- Continuous integration and delivery systems (CI/CD)
- Containerization tools (Docker)
- Application performance monitoring systems
- System log analysis tools
- Test environments for validation and refinement of algorithms
Innovative functionalities
The system had the following innovative functionalities:
- Mechanism for supporting the completion of project forms
- Module for understanding and processing speech in Polish
- Module for analyzing the content of documents with understanding of project context
- Voice assistant enabling natural interactions with the system
- Automatic generation of tasks based on analysis of documents and conversations
- Intelligent analysis of project threats and suggestion of solutions
- Dynamic reporting and visualization of project progress
- Ability to adapt to different types of projects (research, programming, implementation)
- Multi-agent AI system optimizing the work of project teams