
Jak Text2SQL i modele językowe przyspieszają dostęp do danych?
Zespół badaczy reprezentujący Akademię WSEI w Lublinie, z Centrum Badawczo-Rozwojowe Netrix S.A. oraz Politechnikę Lubelską zaprezentował nowatorskie podejście do automatyzacji zapytań do baz danych, wykorzystując technologię Text2SQL w połączeniu z dużymi modelami językowymi (LLM). Opublikowane w czasopiśmie European Research Studies Journal wyniki badań przedstawiają przełomowe obserwacje dotyczące efektywności oraz praktycznych zastosowań modeli Llama3:70b-instruct, Gemma2:27b i Codegemma w kontekście obsługi klienta.
Badanie koncentrowało się na ocenie precyzji oraz szybkości działania wspomnianych modeli językowych przy generowaniu zapytań SQL na podstawie instrukcji wyrażonych w języku naturalnym. Modele Llama3 oraz Gemma2 wykazały wysoką skuteczność, osiągając poprawność odpowiedzi na poziomie 5 z 6 zapytań. Z kolei Codegemma, choć nieco mniej dokładna, zdecydowanie wyróżniała się najkrótszym czasem odpowiedzi, co czyni ją wyjątkowo atrakcyjnym wyborem w zastosowaniach, gdzie kluczowe znaczenie ma szybkość działania.
Co istotne, wyniki eksperymentu podważyły powszechne przekonanie, że dostarczanie modelom szczegółowych schematów baz danych zwiększa ich efektywność. Zespół badawczy wykazał, że nadmiar informacji w kontekście może prowadzić do obniżenia skuteczności i spowolnienia pracy modeli. Zidentyfikowano również potrzebę dalszego rozwoju mechanizmów mapowania synonimów i zrozumienia terminologii branżowej, co jest niezbędne przy obsłudze bardziej złożonych zapytań.
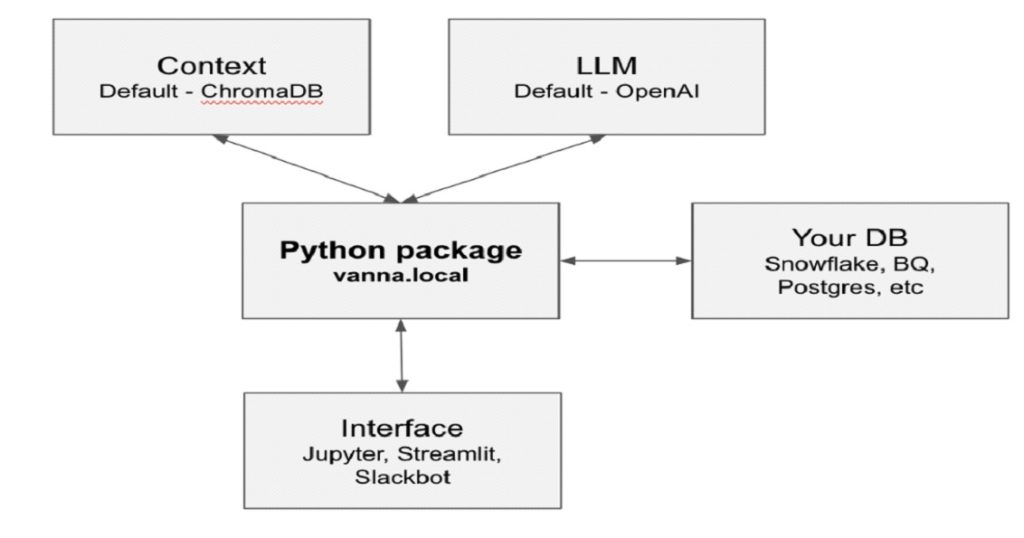
Wprowadzenie technologii Text2SQL do środowiska obsługi klienta eliminuje konieczność znajomości języka SQL przez personel, co znacząco upraszcza proces pozyskiwania danych z baz, skracając czas reakcji oraz minimalizując ryzyko błędów. Przykładem zaawansowanego zastosowania tej technologii jest narzędzie Vanna.AI, które wykorzystuje mechanizm Retrieval Augmented Generation (RAG), łącząc modele językowe z bazami wektorowymi i klasycznymi systemami bazodanowymi. Tego typu architektura umożliwia płynne i kontekstowo trafne formułowanie zapytań, zwiększając efektywność interakcji z systemem.
Wnioski płynące z badania stanowią fundament do dalszego rozwoju inteligentnych narzędzi wspierających automatyzację procesów biznesowych. Autorzy rekomendują upraszczanie kontekstu wejściowego dla modeli, rozwijanie systemów rozpoznawania synonimów oraz dalsze dopasowywanie dużych modeli językowych do specyfiki języka zapytań i dziedzinowych baz danych.
Pełna wersja artykułu dostępna jest pod adresem:
https://ersj.eu/journal/3498