
Konstrukcja technologiczna w projekcie „Narzędzie wspomagające zarządzanie projektami, wdrożeniami obsługę serwisową klientów z wykorzystaniem algorytmów NLP/NLU i rozpoznawania mowy”
Główny cel i problem badawczy
Głównym celem projektu jest opracowanie innowacyjnego systemu wspierającego i automatyzującego procesy zarządzania projektami z wykorzystaniem algorytmów sztucznej inteligencji opartych na metodach analizy języka naturalnego.
Głównym problemem badawczym jest opracowanie zestawu algorytmów i metod analizy treści komunikatów w języku polskim związanych z domeną zarządzania projektami, które umożliwią automatyzację kluczowych procesów związanych z zarządzaniem projektami, wdrożeniami i obsługą serwisową.
Architektura systemu
Projekt korzysta z rozproszonej architektury opartej o mikroserwisy, co pozwoli na zachowanie niezależności poszczególnych modułów oraz umożliwi łatwe rozwijanie systemu w przyszłości bez ingerencji w istniejące moduły. Główne elementy architektury obejmują:
- Architektura mikroserwisowa – każdy moduł funkcjonalny stanowi odrębny serwis
- Magistrala danych – zapewniająca komunikację między modułami
- Interfejsy API – dla komunikacji wewnątrzsystemowej i integracji z systemami zewnętrznymi
- Aplikacje klienckie – webowa i mobilna, zaprojektowane jako intuicyjne, responsywne i dostosowane do różnych urządzeń
Architektura systemu zarządzania projektami z NLP/NLU – szczegółowy opis narzędzi
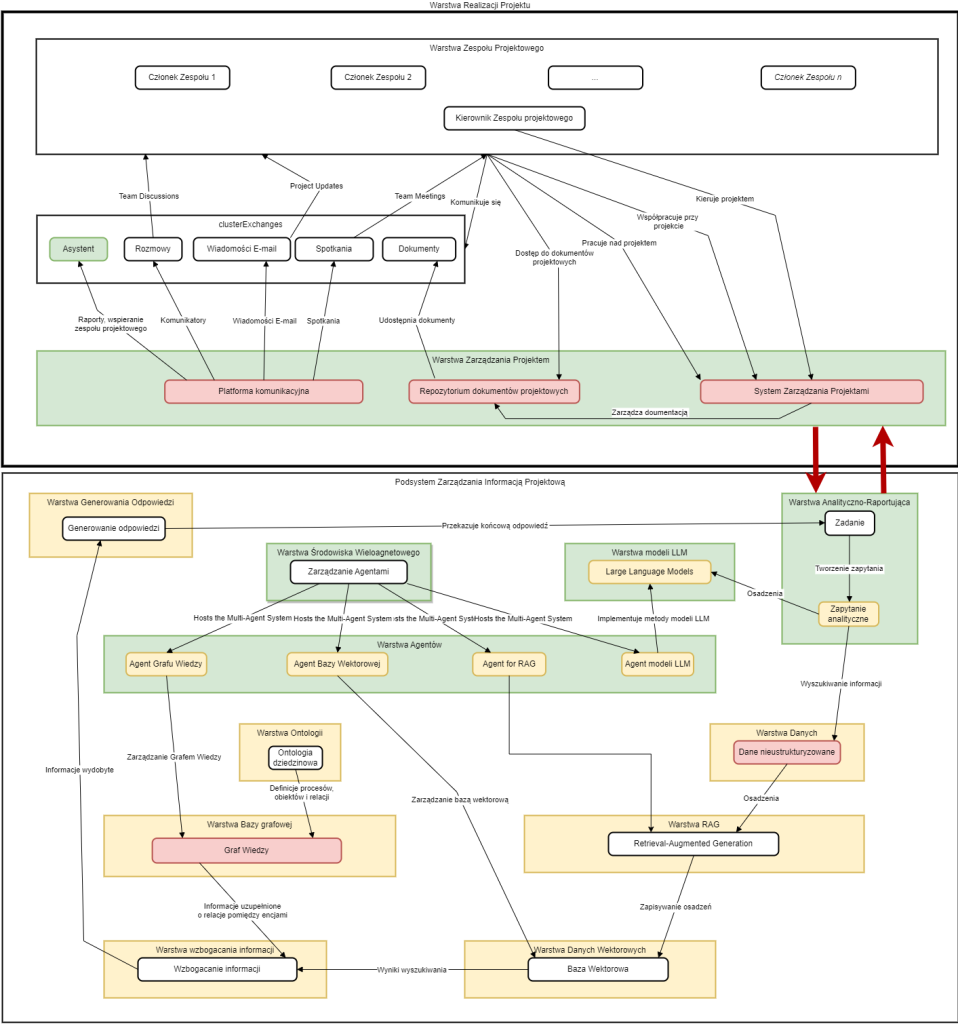
Warstwa realizacji projektu
W ramach systemu zarządzania projektami wykorzystane zostanły narzędzia komunikacyjne i współpracy zespołowej. Systemy komunikacji zespołowej, takie jak Microsoft Teams oraz Slack, służą do efektywnego prowadzenia dyskusji i organizowania spotkań zespołowych, zapewniając ciągłą wymianę informacji między członkami zespołu projektowego. Śledzenie postępów oraz aktualizacji w projektach możliwe jest dzięki dedykowanym narzędziom zarządzania projektami, wśród których znajdą się JIRA, Asana oraz Trello. Kompletna dokumentacja projektowa przechowywana jest i współdzielona przy użyciu specjalistycznych systemów dokumentacyjnych, głównie Confluence oraz SharePoint, co umożliwia centralny dostęp do wszystkich istotnych materiałów projektowych i usprawnia proces współpracy w zespole.
Warstwa realizacji projektu
System wykorzystuje szereg narzędzi służących do kompleksowego przechwytywania danych z różnych źródeł. Asystent wirtualny stanowi kluczowy element systemu i opiera się na interfejsie głosowym wykorzystującym technologię ASR (Automatic Speech Recognition), zaimplementowaną przy użyciu rozwiązań Mozilla DeepSpeech lub Whisper, które zostały dostosowane do specyfiki języka polskiego. Do automatycznego pobierania i analizy wiadomości elektronicznych zastosowano konektory e-mail bazujące na interfejsach API dla usług Gmail oraz Microsoft Exchange. Nagrywanie i transkrypcja spotkań zespołowych realizowane są poprzez dedykowane, własne rozwiązania zbudowane w oparciu o biblioteki PyAudio i librosa, które umożliwiają efektywne przechwytywanie i przetwarzanie dźwięku. W celu digitalizacji dokumentów papierowych wdrożono systemy skanowania dokumentów wykorzystujące technologię OCR, implementowaną za pomocą narzędzi Tesseract lub ABBYY FineReader, zapewniających wysoką dokładność rozpoznawania tekstu. Całość uzupełniają procedury anonimizacji danych, które bazują na własnych algorytmach maskowania danych osobowych, zaprojektowanych zgodnie z wymogami RODO, co gwarantuje pełną ochronę informacji wrażliwych w systemie.
Warstwa zarządzania projektem
W systemie zarządzania projektami zaimplementowano platformy integracyjne, które zapewniają spójne funkcjonowanie wszystkich komponentów. Platforma komunikacyjna bazuje na architekturze mikroserwisowej, wykorzystującej technologie Spring Boot lub Django, oraz jest wspierana przez wydajny system kolejkowania wiadomości, taki jak RabbitMQ lub Kafka, co zapewnia niezawodną wymianę informacji między komponentami systemu. Dla efektywnego przechowywania dokumentacji projektowej wdrożono repozytorium dokumentów, które może być zrealizowane jako system plików rozproszonych (HDFS) lub specjalizowane bazy dokumentów, takie jak MongoDB czy Elasticsearch, w zależności od konkretnych wymagań projektu. Centralnym elementem całego rozwiązania jest System Zarządzania Projektami, który został zaprojektowany jako autorskie rozwiązanie oparte na nowoczesnym API RESTful, zapewniającym elastyczną integrację z popularnymi narzędziami zewnętrznymi poprzez dedykowane interfejsy programistyczne, takie jak JIRA API.
Podsystem zarządzania informacją projektową
Warstwa modeli LLM
System wykorzystuje technologie przetwarzania języka naturalnego, które zostały starannie dobrane do wymagań projektu. W zakresie modeli językowych zastosowano zarówno dostosowane (fine-tuned) wersje popularnych modeli Gemma3, jak i własne modele LLM zbudowane w oparciu o architekturę transformerów, szczególnie XLM-RoBERTa, które zostały specjalnie przystosowane do efektywnej pracy z językiem polskim. Implementacja funkcjonalności NLP opiera się na uznanych bibliotekach, takich jak HuggingFace Transformers oraz SpaCy, przy czym dla tej drugiej wykorzystywane są polskie modele językowe, w szczególności pl_core_news_lg, zapewniające wysoką jakość analizy tekstu w języku polskim. Proces dostosowywania modeli do specyficznych potrzeb domeny zarządzania projektami realizowany jest przy użyciu narzędzi douczania (fine-tuning), wśród których kluczową rolę odgrywa PyTorch Lightning, umożliwiający efektywne i zoptymalizowane douczanie modeli na specjalistycznych zbiorach danych związanych z zarządzaniem projektami.
Warstwa środowiska wieloagentowego
System wykorzystuje rozwiązania w zakresie architektury agentowej, które tworzą spójną platformę do koordynacji procesów AI. Jako podstawowy framework agentowy zastosowano LangGraph, który został wybrany ze względu na jego większą rozszerzalność w porównaniu do alternatywnych rozwiązań, takich jak LangChain, co umożliwia bardziej elastyczne dostosowanie do wymagań projektu. Integracja z istniejącą infrastrukturą mikroserwisową realizowana jest poprzez specjalnie zaprojektowane, customowe rozszerzenia LangGraph, które zapewniają bezproblemową komunikację poprzez standardowe interfejsy REST oraz gRPC. W celu optymalizacji wydajności przetwarzania danych wdrożono system orkiestracji oparty na Ray, który umożliwia efektywne równoległe przetwarzanie zadań i jest natywnie wspierany przez LangGraph, co eliminuje potrzebę implementacji dodatkowych warstw integracyjnych.
Warstwa agentów
W systemie zaimplementowano architekturę agentową, która stanowi kluczowy element całego rozwiązania. Agenty zostały zdefiniowane jako komponenty LangGraph z dołączonymi customowymi narzędziami, co pozwala na precyzyjne dostosowanie ich funkcjonalności do specyficznych wymagań projektu. Komunikacja i koordynacja między poszczególnymi agentami odbywa się poprzez wspólną pamięć kontekstową, realizowaną za pomocą mechanizmu LangGraph State Manager, który umożliwia efektywne dzielenie się informacjami i zachowanie spójności w całym procesie przetwarzania. W celu zapewnienia elastycznej integracji z zewnętrznymi systemami i bazami danych, takimi jak Neo4j, Pinecone i inne, opracowano specjalne adaptery implementowane jako narzędzia LangGraph, które standaryzują komunikację i upraszczają proces wymiany danych między agentami a infrastrukturą zewnętrzną.
Warstwa ontologii
W systemie zaimplementowano mechanizmy zarządzania ontologią, które zapewniają strukturalną reprezentację wiedzy dziedzinowej. Do tworzenia i zarządzania ontologią dziedzinową wykorzystywany jest Protégé, renomowany edytor ontologii, który oferuje intuicyjny interfejs umożliwiający modelowanie złożonych struktur wiedzy z obszaru zarządzania projektami. Reprezentacja ontologii opiera się na uznanych standardach, takich jak OWL (Web Ontology Language) oraz RDF (Resource Description Framework), które zapewniają formalną strukturę i interoperacyjność wiedzy w systemie. Dla zapewnienia możliwości automatycznego wnioskowania na podstawie zgromadzonej wiedzy, system wykorzystuje zaawansowane silniki wnioskowania, takie jak Apache Jena lub OWLReady2, które realizują operacje wnioskowania logicznego na ontologii, umożliwiając wydobywanie ukrytych relacji i generowanie nowej wiedzy na podstawie istniejących faktów.
Warstwa bazy grafowej
W systemie wykorzystano Neo4j jako główną bazę danych do przechowywania grafów wiedzy, co pozwala na efektywne reprezentowanie złożonych relacji między encjami projektowymi. Do wyszukiwania i analizy związków w grafie wiedzy zastosowano język zapytań Cypher, który umożliwia precyzyjne formułowanie kwerend i efektywne przeszukiwanie struktur grafowych. Wizualizację relacji zapisanych w grafie wiedzy realizują biblioteki Neo4j Bloom lub D3.js, które przekształcają abstrakcyjne struktury danych w czytelne reprezentacje graficzne, ułatwiające zrozumienie zależności między elementami projektowymi.
Warstwa Danych Wektorowych
W systemie wykorzystano Weaviate lub Qdrant jako bazy wektorowe służące do indeksowania i wyszukiwania wektorowych reprezentacji dokumentów projektowych. Do generowania embedingów dla tekstów w języku polskim zastosowano bibliotekę SentenceTransformers wraz z modelami wielojęzycznymi, które przekształcają dokumenty tekstowe na reprezentacje wektorowe zachowujące znaczenie semantyczne. Analizę i wizualizację wielowymiarowej przestrzeni wektorowej umożliwiają algorytmy redukcji wymiarowości, takie jak UMAP i t-SNE, które pozwalają na przekształcenie złożonych struktur wektorowych do postaci umożliwiającej ich interpretację wizualną przez użytkowników systemu.
Warstwa RAG
W systemie zaimplementowano warstwę RAG (Retrieval-Augmented Generation) jako własne rozwiązanie oparte na architekturze modułowej, co umożliwia elastyczne dostosowanie komponentów do specyficznych potrzeb projektu. Wyszukiwanie informacji realizowane jest poprzez metody hybrydowe, które łączą algorytm BM25 z miarą podobieństwa kosinusowego, zapewniając wyższą skuteczność odnajdywania relewantnych dokumentów niż każda z tych metod stosowana osobno. Przetwarzanie kontekstu w systemie wykorzystuje techniki takie jak sliding window chunking do segmentacji dokumentów, reranking wyników wyszukiwania do wyboru najbardziej odpowiednich fragmentów oraz dynamiczna kompresja kontekstu, która optymalizuje ilość informacji przekazywanych do modelu językowego.
Warstwa Generowania Odpowiedzi
W systemie zastosowano warstwę generowania odpowiedzi opartą na dostosowanych (fine-tuned) modelach Bloom lub Phi-3, które zostały specjalnie przystosowane do specyfiki domeny zarządzania projektami. Kontrola jakości generowanych odpowiedzi realizowana jest przez mechanizm ensemble learning, który wykorzystuje wiele modeli równocześnie do weryfikacji spójności i zgodności tworzonych treści. W celu minimalizacji zjawiska halucynacji, czyli generowania nieprawdziwych informacji, system wykorzystuje metody fact verification, które weryfikują generowane treści poprzez porównanie ich z faktami zapisanymi w bazie wiedzy oraz strukturach ontologicznych.
Warstwa Analityczno-Raportująca
W systemie funkcjonuje warstwa analityczno-raportująca wykorzystująca narzędzia Business Intelligence, takie jak PowerBI oraz Tableau, które zostały zintegrowane z API systemu, umożliwiając dynamiczną wizualizację danych projektowych. Do generowania raportów zastosowano silniki JasperReports lub własne rozwiązanie implementowane w React.js, które przekształcają dane projektowe w czytelne dokumenty dostosowane do potrzeb użytkowników. Wykrywanie potencjalnych problemów w projektach realizuje dedykowany moduł wykorzystujący algorytmy oparte zarówno na predefiniowanych regułach, jak i technikach uczenia maszynowego implementowanych przy użyciu biblioteki Scikit-learn.
Warstwa Infrastruktury
W systemie zastosowano warstwę infrastruktury opartą na wielu komplementarnych rozwiązaniach. Orkiestracja kontenerów realizowana jest przez Kubernetes, który zarządza mikroserwisami i zapewnia ich skalowalność oraz niezawodność działania. Procesy ciągłej integracji i wdrażania obsługiwane są przez system CI/CD, wykorzystujący GitLab CI lub GitHub Actions, co umożliwia automatyczne testowanie i wdrażanie nowych wersji oprogramowania. Monitoring działania systemu oraz centralizacja logów zapewnione są przez zestaw narzędzi obejmujący Prometheus do zbierania metryk, Grafanę do ich wizualizacji oraz ELK Stack (Elasticsearch, Logstash, Kibana) do kompleksowej analizy logów. Bezpieczeństwo systemu opiera się na mechanizmach OAuth 2.0 i JWT stosowanych do uwierzytelniania i autoryzacji użytkowników, a także na regularnych testach penetracyjnych weryfikujących odporność systemu na potencjalne ataki.
Interfejsy użytkownika
Interfejs webowy systemu został zbudowany przy użyciu biblioteki React.js wraz z komponentami Material-UI, co zapewnia spójny wygląd i funkcjonalność zarówno dla administratorów, jak i zwykłych użytkowników. Dostęp mobilny do systemu umożliwia aplikacja stworzona w technologii React Native lub Flutter, która oferuje kluczowe funkcjonalności systemu na urządzeniach przenośnych. Uzupełnieniem tradycyjnych interfejsów jest interfejs konwersacyjny w postaci własnego rozwiązania chatbota, które zostało zintegrowane z asystentem głosowym, umożliwiając użytkownikom interakcję z systemem za pomocą języka naturalnego.
System jako całość implementuje architekturę event-driven, gdzie komunikacja między komponentami odbywa się przez brokerów wiadomości (Kafka), co zapewnia skalowalność i odporność na awarie. Kluczowe aspekty integracji obejmują standaryzowane API RESTful dla komunikacji między serwisami oraz mechanizmy Circuit Breaker (np. Resilience4j) dla zapewnienia odporności na błędy.
Technologie i narzędzia AI
System wykorzystuje zaawansowane technologie AI, zintegrowane w spójną architekturę mikroserwisową:
Duże modele językowe (LLM) zintegrowane z bazami wiedzy i wiedzą domenową
W systemie wykorzystywane są duże modele językowe zintegrowane z bazami wiedzy domenowej. Podstawowymi modelami LLM w systemie są GPT-4 oraz Gemma 3, dostępne poprzez interfejsy programistyczne OpenAI API lub Ollama API. Dla zadań specyficznych dla języka polskiego system korzysta z modeli specjalizowanych, takich jak platforma HerBERT, która stanowi polską implementację architektury BERT, oraz model plT5 dostosowany do przetwarzania polskich tekstów. Dostosowanie tych modeli do specyficznej domeny zarządzania projektami realizowane jest poprzez mechanizmy fine-tuningu wykorzystujące biblioteki DeepSpeed oraz PEFT (Parameter-Efficient Fine-Tuning), które pozwalają na efektywne dostrojenie parametrów modeli przy ograniczonych zasobach obliczeniowych. Integrację modeli z bazami wiedzy zapewniają komponenty Langchain DocumentLoaders oraz TextSplitters, które umożliwiają przetwarzanie i segmentację dokumentacji projektowej do formatu odpowiedniego dla modeli językowych. System stosuje również techniki optymalizacji kontekstu, w tym auto-merging retrieval, które dynamicznie dostosowuje długość kontekstu przekazywanego do modelu w zależności od złożoności zapytania i dostępnych zasobów.
Metody RAG (Retrieval-Augmented Generation) do dodawania kontekstu semantycznego
W systemie wykorzystywane są metody RAG (Retrieval-Augmented Generation) służące do dodawania kontekstu semantycznego. Podstawową infrastrukturę RAG stanowi LlamaIndex, który oferuje spójny ekosystem narzędzi do pracy z dokumentami i modelami językowymi. Indeksowanie dokumentów realizowane jest przez komponent LlamaIndex ServiceContext z konfiguracją embedderów dostosowanych specjalnie dla języka polskiego. System wykorzystuje strategie wyszukiwania w postaci LlamaIndex Hybrid Search, który łączy algorytm BM25 z wyszukiwaniem semantycznym, co pozwala na precyzyjne odnajdywanie relewantnych fragmentów dokumentów. Śledzenie kontekstu rozmowy zapewniają komponenty LlamaIndex’s TextCorpus oraz ConversationalRetrievalChain, które przechowują historię interakcji i uwzględniają ją w kolejnych odpowiedziach. Filtrowanie i porządkowanie wyników wyszukiwania odbywa się przy użyciu LlamaIndex’s node postprocessors wraz z CustomFilters, które zostały dostosowane do konkretnych potrzeb projektowych. Wzbogacanie kontekstu realizowane jest przez MetadataReplacementPostProcessor, który dynamicznie uzupełnia kontekst o dodatkowe metadane projektowe, zwiększając trafność generowanych odpowiedzi.
Grafy wiedzy pozwalające na tworzenie uporządkowanych reprezentacji bytów i relacji
System wykorzystuje grafy wiedzy do tworzenia uporządkowanych reprezentacji bytów i relacji. Jako bazę grafową zastosowano Neo4j wraz z Graph Data Science Library, która umożliwia przeprowadzanie analiz algorytmicznych na strukturach grafowych. Modelowanie struktury grafu odbywa się przy użyciu narzędzia Neo4j Arrows, które pozwala na wizualne projektowanie modelu grafu wiedzy i ułatwia zrozumienie złożonych relacji. Zarządzanie ontologią realizowane jest poprzez Neo4j SHACL, służące do definiowania i walidacji schematów danych w grafie. Interfejs do grafu zapewnia komponent Neosemantics (n10s), który umożliwia integrację standardów RDF i OWL z bazą Neo4j. Zapytania do grafu wykonywane są za pomocą języka Cypher oraz komponentu LlamaIndex’s Neo4jIndex, co pozwala na semantyczne przeszukiwanie struktury grafowej. Generowanie grafu w systemie wspomaga Llama Index EntityExtractor, który automatycznie rozpoznaje encje i relacje w tekście, przekształcając dane nieustrukturyzowane w uporządkowane struktury grafowe.
Algorytmy NLP/NLU do ekstrahowania informacji z danych tekstowych
System wykorzystuje algorytmy NLP/NLU do efektywnego ekstrahowania informacji z danych tekstowych. Podstawowe przetwarzanie tekstu realizowane jest przez bibliotekę SpaCy z wykorzystaniem modelu pl_core_news_lg dostosowanego do specyfiki języka polskiego. Rozpoznawanie encji (Named Entity Recognition) opiera się na mechanizmach SpaCy z modelami dostosowanymi do domeny projektowej, co umożliwia identyfikację kluczowych elementów w dokumentach. Ekstrakcja relacji między encjami odbywa się przy użyciu LlamaIndex’s Relation Extraction, która została zmodyfikowana dla lepszej obsługi polskich struktur językowych. Kategoryzacja tekstu w systemie bazuje na bibliotece Transformers z modelem DistilBERT, który został dostrojony (fine-tuned) na danych projektowych. Do wykrywania potencjalnych problemów projektowych służy analiza sentymentu realizowana przez model HerBERT z dedykowanym modułem klasyfikacji. Ekstrakcja słów kluczowych wykorzystuje narzędzie KeyBERT wraz z polskimi embedingami, co umożliwia automatyczne tagowanie dokumentów. Przetwarzanie dokumentów prawnych prowadzone jest z wykorzystaniem narzędzi Docusaurus oraz customowego ekstraktora encji, specjalnie zaprojektowanego dla dokumentacji projektowej.
Technologie ASR (automatycznego rozpoznawania mowy) do przetwarzania danych głosowych
W systemie stosowany jest silnik ASR oparty na modelu Wav2Vec2-XLS-R-300M, który został dostosowany do specyfiki języka polskiego i funkcjonuje pod oznaczeniem wav2vec2-xls-r-300m-pl-cv8. Przygotowanie danych dźwiękowych realizowane jest przy użyciu bibliotek Librosa i PyDub, które umożliwiają przetwarzanie i analizę sygnałów audio. Transkrypcja mowy w czasie rzeczywistym wykorzystuje technologie WebRTC oraz Socket.io, które zapewniają efektywne przesyłanie strumieni audio między komponentami systemu. Rozpoznawanie poszczególnych mówców podczas spotkań projektowych realizowane jest przez bibliotekę pyannote.audio, która przeprowadza diaryzację mowy i przypisuje wypowiedzi do konkretnych osób. Normalizacja transkrybowanego tekstu odbywa się z wykorzystaniem własnych reguł dostosowanych do języka polskiego, implementowanych przy użyciu biblioteki spaCy. Wykrywanie intencji użytkowników w wypowiedziach głosowych zapewnia framework Rasa NLU z zestawem intencji dostosowanych do domeny zarządzania projektami. Konwersja tekstu na mowę realizowana jest przez model FastSpeech 2 współpracujący z polskimi modelami głosowymi, co pozwala na generowanie naturalnie brzmiących komunikatów głosowych.
Środowiska wieloagentowe z wyspecjalizowanymi agentami
System wykorzystuje środowisko wieloagentowe składające się z wyspecjalizowanych agentów odpowiedzialnych za różne zadania. Głównym koordynatorem działań w tym środowisku jest framework orkiestracji oparty na LangChain Agent Supervisor architecture, który zarządza przepływem pracy i przydziałem zadań. Komunikacja między poszczególnymi agentami odbywa się dzięki protokołowi LangChain AgentExecutor z komponentem MessageHistory, który zapewnia spójny przepływ informacji i zachowanie kontekstu rozmowy. System obejmuje sześć typów wyspecjalizowanych agentów. Agent Grafu Wiedzy bazuje na LangChain Neo4jToolkit z zestawem dostosowanych narzędzi Cypher, umożliwiających operacje na bazie grafowej. Agent Bazy Wektorowej wykorzystuje LangChain VectorStoreToolkit skonfigurowany dla bazy Qdrant, co pozwala na efektywne wyszukiwanie semantyczne. Agent RAG funkcjonuje na bazie LangChain RetrievalQA z konfiguracją chain_type=”refine”, umożliwiającą stopniowe udoskonalanie odpowiedzi. Agent LLM wykorzystuje LangChain LLMChain wraz z konfigurowalnymi szablonami promptów dostosowanymi do kontekstu projektowego. Agent Zadaniowy opiera się na komponencie LangChain PlanAndExecute z bezpośrednim dostępem do API systemu zarządzania projektami, co umożliwia planowanie i realizację konkretnych zadań projektowych. Agent Formularzy wykorzystuje LangChain TextMapReduceChain do automatycznego uzupełniania formularzy projektowych na podstawie dostępnych danych i kontekstu.
Integracja wszystkich komponentów AI
W systemie zastosowano szereg elementów zapewniających spójność integracji komponentów AI. Warstwę abstrakcji stanowi LangChain Tools, który działa jako uniwersalne API dla wszystkich komponentów AI, zapewniając jednolity interfejs dostępu. Monitorowanie i logowanie działań agentów realizuje mechanizm orkiestracji oparty na LangChain callbacks, który rejestruje przebieg procesów i umożliwia ich analizę. Do budowania i przechowywania historii projektu służy pamięć długoterminowa zaimplementowana jako LangChain’s ConversationSummaryMemory, która tworzy skondensowane podsumowania wcześniejszych interakcji. Centralnym elementem integracji jest serwer koordynujący oparty na FastAPI, udostępniający endpointy dla wszystkich funkcjonalności AI i zarządzający przepływem danych w systemie. Komunikację asynchroniczną między komponentami zapewnia magistrala zdarzeń Kafka, która umożliwia niezależne działanie poszczególnych elementów systemu. Śledzenie wydajności modeli językowych realizuje narzędzie Weights & Biases, które gromadzi metryki i umożliwia optymalizację działania systemu. Szybki dostęp do podobnych kontekstów zapewnia Redis Vector Search, działający jako cache wektorowy, który przyspiesza wyszukiwanie semantycznie zbliżonych informacji.
Bezpieczeństwo i zarządzanie modelami
System wykorzystuje szereg narzędzi zapewniających bezpieczeństwo i właściwe zarządzanie modelami AI. Kontrola dostępu do funkcjonalności AI realizowana jest przez Langfuse, który zarządza uprawnieniami użytkowników i monitoruje wykorzystanie zasobów. Wersjonowanie modeli odbywa się przy pomocy MLflow, które śledzi wersje, parametry oraz wyniki działania poszczególnych modeli w środowisku produkcyjnym. Monitorowanie jakości danych wejściowych zapewnia narzędzie Evidently, które wykrywa dryft danych i alarmuje o potencjalnych problemach z jakością danych. Sanityzację i walidację promptów realizuje PromptArmor, który chroni system przed atakami przez manipulację promptami. Do automatycznej oceny odpowiedzi generowanych przez mechanizmy RAG służy narzędzie RAGAS, które mierzy jakość i trafność generowanych treści. Identyfikację i maskowanie danych poufnych w dokumentach zapewnia Presidio od Microsoft, który rozpoznaje i zabezpiecza wrażliwe informacje, takie jak dane osobowe czy finansowe.
Bazy danych i zarządzanie danymi
W systemie zastosowano różnorodne typy baz danych, które są wykorzystywane do przechowywania i przetwarzania specyficznych rodzajów danych. Relacyjna baza danych służy do przechowywania struktur projektowych, zapewniając efektywne zarządzanie informacjami o projektach, zadaniach i użytkownikach. Ontologie i bazy wiedzy opisują integrację danych tekstowych i głosowych z procesami projektowymi, co pozwala na semantyczne powiązanie różnych typów informacji. Specjalna baza danych przechowuje zapisy próbek dźwiękowych pochodzących z konwersacji, korespondencji e-mail oraz dokumentacji, co umożliwia analizę komunikacji projektowej. System implementuje również metody i procedury anonimizacji danych, które chronią prywatność i dane osobowe uczestników projektów. Wektorowe bazy danych pełnią rolę magazynu osadzonych (embeddings) reprezentacji dokumentów, umożliwiając semantyczne wyszukiwanie i porównywanie treści. Całość uzupełnia system zarządzania grafem wiedzy, który przechowuje i wizualizuje relacje między obiektami projektowymi, wspierając złożone zapytania i analizy.
Komponenty funkcjonalne systemu
System składa się z następujących modułów:
- Moduł pozyskiwania danych:
- Konektory do wielu źródeł (e-mail, komunikatory, dokumentacja projektowa, dokumenty papierowe)
- Algorytmy przetwarzania i wstępnej analizy danych
- Gromadzenie dokumentów różnego pochodzenia związanych z dziedziną zarządzania projektami
- Moduł NLP/NLU:
- Algorytmy oparte na metodach rozumienia tekstu dokonujące kategoryzacji tekstu
- Algorytmy ekstrakcji cech i parametrów z dokumentów i rozmów
- Moduł umożliwiający zamianę sygnału mowy na tekst oraz jego analizę semantyczną
- Metody fine-tuning modeli uczenia maszynowego
- Moduł asystenta głosowego:
- Techniki ASR do interakcji i komunikacji z uczestnikami projektów
- Algorytmy wykrywania intencji użytkownika
- Funkcje automatycznego generowania sugestii, podpowiedzi i zaleceń na podstawie analizy kontekstu
- Integracja z bazą wiedzy do uzyskiwania informacji o projektach i odpowiedzialnych osobach
- Moduł analityczny:
- Algorytmy do identyfikacji zagrożeń i sugerowania odpowiednich działań
- Systemy generowania raportów i analiz związanych z realizacją projektów
- Narzędzia wizualizacji danych projektowych
- Moduł zarządzania projektami:
- Mechanizm automatycznego uzupełniania formularzy projektowych
- System automatyzacji procesów zarządzania projektami
- Narzędzia do projektowania formularzy dla różnych typów projektów
- Mechanizmy przypisywania zadań i wsparcia procesów decyzyjnych
Interfejsy użytkownika
System dostępny jest poprzez:
- Aplikację webową – interfejs dostępny z poziomu przeglądarki
- Aplikację mobilną – dla dostępu z urządzeń przenośnych
- Interfejs głosowy – asystent głosowy umożliwiający naturalne interakcje z systemem
Integracje z systemami zewnętrznymi
System integruje się z:
- Systemami zarządzania projektami i zadaniami (np. Jira, MS Azure DoevOps)
- Narzędziami do kontroli wersji (np. Git)
- Kalendarzami i systemami harmonogramowania
- Systemami komunikacji (e-mail, komunikatory)
- Systemami dokumentacji
Protokoły i standardy komunikacji
Projekt wykorzystuje następujące protokoły i standardy:
- REST API dla komunikacji między modułami i systemami zewnętrznymi
- WebSocket dla komunikacji w czasie rzeczywistym
- JSON/XML do wymiany danych
- OAuth/JWT dla autoryzacji i uwierzytelniania
- HTTPS dla bezpiecznej komunikacji
Aspekty bezpieczeństwa
Projekt uwzględnia zapewnienie integralności i bezpieczeństwa danych. System zapewnia:
- Metody anonimizacji danych
- Odporność na metody ataku na bazy danych
- Szyfrowanie danych w spoczynku i podczas transmisji
- Systemy kontroli dostępu i autoryzacji
- Monitoring i audyt bezpieczeństwa
Technologie wspomagające rozwój
- Systemy ciągłej integracji i dostarczania (CI/CD)
- Narzędzia do konteneryzacji (Docker)
- Systemy monitorowania wydajności aplikacji
- Narzędzia do analizy logów systemu
- Środowiska testowe do walidacji i udoskonalania algorytmów
Innowacyjne funkcjonalności
System posiadał następujące innowacyjne funkcjonalności:
- Mechanizm wspomagania uzupełniania formularzy projektowych
- Moduł rozumienia oraz przetwarzania mowy w języku polskim
- Moduł analizy treści dokumentów z rozumieniem kontekstu projektowego
- Asystent głosowy umożliwiający naturalne interakcje z systemem
- Automatyczne generowanie zadań na podstawie analizy dokumentów i rozmów
- Inteligentna analiza zagrożeń projektowych i sugerowanie rozwiązań
- Dynamiczne raportowanie i wizualizacja postępów projektu
- Możliwość adaptacji do różnych typów projektów (badawczych, programistycznych, wdrożeniowych)
- Wieloagentowy system AI optymalizujący pracę zespołów projektowych