
Konstrukcja technologiczna w projekcie „Inteligentny system przetwarzania mowy w transkrypcji medycznej”
Główny cel i problem badawczy
Głównym celem projektu jest opracowanie funkcjonalnego systemu wspierającego pacjentów i lekarzy w prowadzeniu elektronicznej dokumentacji medycznej podczas wizyty lekarskiej z wykorzystaniem zaawansowanych algorytmów NLP/NLU w języku polskim. System ten znacząco ograniczy czas poświęcany na ręczne wprowadzanie danych, co obecnie prowadzi do nadmiarowej pracy, stresu i wypalenia zawodowego wśród personelu medycznego.
Kluczowym problemem badawczym jest opracowanie zbioru algorytmów uczenia maszynowego oraz NLP/NLU dla języka polskiego, które umożliwią transkrypcję wywiadów medycznych, wydobywanie istotnych informacji z tekstu oraz automatyczne uzupełnianie formularzy medycznych. Rozwiązanie tego problemu znacząco poprawi efektywność pracy lekarzy, skróci kolejki pacjentów i podwyższy jakość dokumentacji medycznej.
Główne funkcjonalności systemu
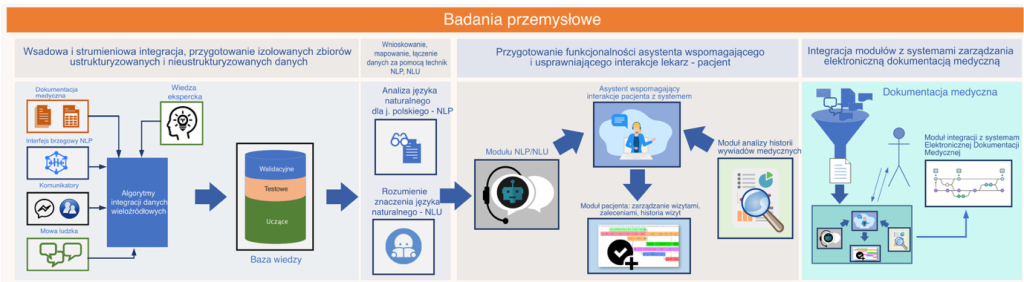
System zapewnia kompleksowe wsparcie dla procesu dokumentacji medycznej poprzez szereg kluczowych funkcjonalności. Rejestracja i odtwarzanie dźwięku podczas wizyty lekarskiej realizowane są przez dedykowane urządzenie brzegowe z dwukanałowym systemem nagrywania, umożliwiającym separację głosów lekarza i pacjenta. System umożliwia tworzenie kwestionariuszy medycznych i elastyczne zarządzanie nimi, pozwalając na dostosowanie do specjalizacji lekarskich i indywidualnych potrzeb placówek medycznych.
Innowacyjnym rozwiązaniem jest prowadzenie wizyty kontrolowanej przy zastosowaniu dynamicznych scenariuszy opartych na AI, które podpowiadają lekarzowi kolejne pytania na podstawie analizy dotychczasowej rozmowy. Transkrypcja rozmowy w czasie rzeczywistym, realizowana przez zaawansowane modele rozpoznawania mowy, umożliwia natychmiastową dostępność tekstu konsultacji. Automatyczne wypełnianie formularzy na podstawie analizy semantycznej transkrypcji eliminuje konieczność ręcznego wprowadzania danych przez personel medyczny.
System zapewnia również synchronizację danych z chmurą obliczeniową, ułatwiając dostęp do dokumentacji z różnych lokalizacji i urządzeń. Generowanie dokumentów takich jak recepty, zwolnienia lekarskie czy skierowania odbywa się automatycznie na podstawie zgromadzonych danych. Aplikacja mobilna wyposażona w wirtualnego asystenta przeprowadza pacjenta przez cały proces wizyty, umożliwia przesyłanie dokumentów uzupełniających oraz zapewnia dostęp do historii wizyt i zaleceń.
Architektura technologiczna
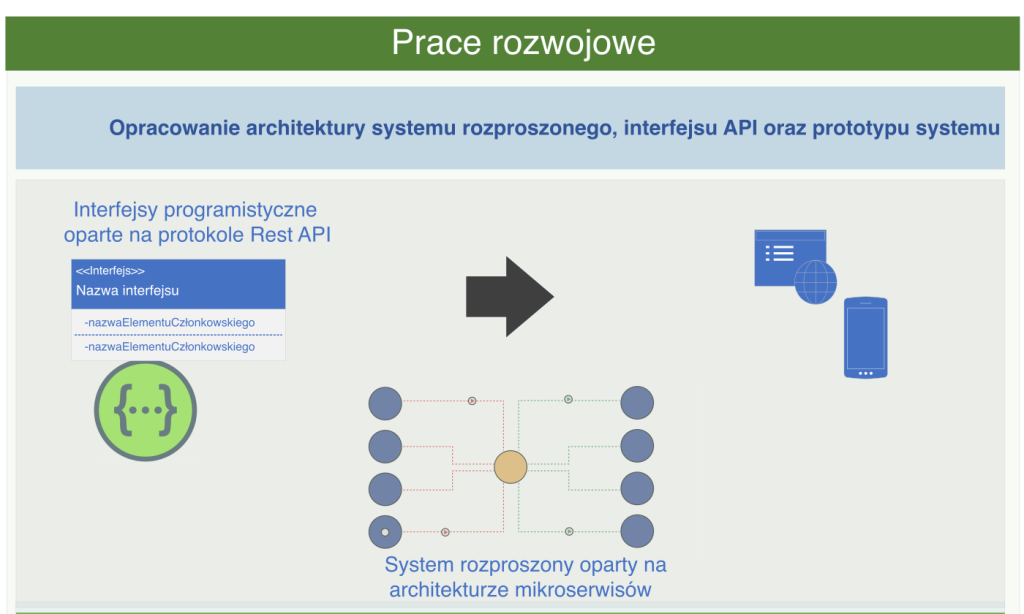
System wykorzystuje nowoczesną architekturę mikroserwisów, zapewniającą elastyczność, wydajność i skalowalność platformy. Mikroserwisy implementowane są głównie przy użyciu FastAPI (Python), co umożliwia optymalny dobór technologii do konkretnych zadań. Komunikacja między serwisami realizowana jest przez brokera wiadomości Kafka, który pełni rolę szyny danych i umożliwia niezawodne przesyłanie komunikatów między komponentami.
Konteneryzacja z wykorzystaniem Dockera zapewniają jednolite środowisko uruchomieniowe oraz elastyczne zarządzanie zasobami systemu. Główne interfejsy API implementowane są zgodnie ze standardem REST i dokumentowane przy użyciu OpenAPI, co ułatwia integrację z systemami zewnętrznymi. Transmisja dźwięku w czasie rzeczywistym wykorzystuje protokół WebSocket, zapewniający niskie opóźnienia i responsywność interfejsu.
Cała infrastruktura wdrażana jest z wykorzystaniem technik ciągłej integracji i wdrażania (CI/CD) poprzez Azure Pipelines, co umożliwia automatyzację procesów kompilacji, testowania i wdrażania nowych wersji oprogramowania. Bezpieczeństwo danych zapewniają mechanizmy uwierzytelniania oparte na JWT, wspierane przez centralne zarządzanie tożsamością.
Rozpoznawanie mowy i przetwarzanie języka naturalnego
Serce systemu stanowią zaawansowane technologie rozpoznawania mowy i przetwarzania języka naturalnego, dostosowane do specyfiki języka polskiego. Transkrypcja mowy realizowana jest przez model OpenAI Whisper, który został dostosowany do rozpoznawania polskiej terminologii medycznej. Rozpoznawanie mowy wspierane jest również przez Mozilla DeepSpeech, zapewniający możliwość lokalnego przetwarzania danych audio bez konieczności ich przesyłania do chmury.
Przetwarzanie języka naturalnego bazuje na modelach z biblioteki HuggingFace Transformers, w szczególności na polskich wariantach BERT (HerBERT) dostosowanych do analizy tekstów medycznych. Rozpoznawanie encji medycznych, klasyfikacja semantyczna i ekstrakcja relacji realizowane są przy użyciu biblioteki SpaCy z polskimi modelami językowymi. System wykorzystuje modele LLM (Large Language Model), np. Gemma3, które po procesie fine-tuningu na specjalistycznych tekstach medycznych służą do generowania dokumentacji oraz analizy kontekstu rozmowy.
Automatyczne mapowanie informacji z transkrypcji na pola formularzy realizowane jest przez niestandardowe algorytmy zbudowane na bazie PyTorch, wykorzystujące techniki uczenia ze wzmocnieniem. Generowanie tekstu wspomagane jest przez techniki Retrieval Augmented Generation wykorzystujące LangChain do integracji modeli LLM z bazami wiedzy medycznej.
Urządzenia brzegowe i przetwarzanie dźwięku
System wykorzystuje dedykowane urządzenia brzegowe do rejestracji i wstępnego przetwarzania dźwięku. Urządzenia te wyposażone są w zaawansowane układy NVIDIA dla przetwarzania brzegowego z akceleracją AI, co umożliwia wstępną analizę dźwięku bez konieczności przesyłania surowych danych do chmury. Urządzenie prowadzi dwukanałową rejestrację dźwięku z częstotliwością próbkowania 44100 Hz, co pozwala na przechwytywanie pełnego spektrum ludzkiej mowy.
Przetwarzanie sygnału audio realizowane jest przy użyciu bibliotek PyAudio i librosa, umożliwiających filtrację szumów, normalizację głośności i separację źródeł dźwięku. Diaryzacja mowy (rozpoznawanie poszczególnych mówców) implementowana jest przy użyciu PyAnnote, co pozwala na precyzyjne przypisanie poszczególnych wypowiedzi do lekarza i pacjenta. Strumieniowanie audio w czasie rzeczywistym wykorzystuje WebRTC, zapewniając wysoką jakość i niskie opóźnienia transmisji.
Bazy danych i zarządzanie informacją
System implementuje wielowarstwową architekturę przechowywania danych, dostosowaną do różnych typów informacji medycznych. Strukturalne dane pacjentów i dokumentacji medycznej przechowywane są w relacyjnej bazie PostgreSQL, zapewniającej integralność i transakcyjność. Nagrania audio i załączniki przechowywane są w systemie obiektowym MinIO, oferującym skalowalność i odporność na awarie.
Przechowywanie i wyszukiwanie informacji semantycznych realizowane jest poprzez bazę wektorową Qdrant, która umożliwia efektywne odnajdowanie podobnych dokumentów i fragmentów tekstu na podstawie ich znaczenia. Grafowe reprezentacje terminologii medycznej i relacji między pojęciami przechowywane są w Neo4j, co pozwala na złożone zapytania uwzględniające semantyczne powiązania.
Interfejsy użytkownika i dostępność
System oferuje zróżnicowane interfejsy użytkownika dostosowane do potrzeb różnych grup odbiorców. Główny interfejs webowy dla lekarzy implementowany jest przy użyciu React z biblioteką komponentów Material-UI, zapewniającą nowoczesny i intuicyjny wygląd. Interfejs mobilny dla pacjentów zbudowany jest w React Native, oferując spójne doświadczenie użytkownika na urządzeniach iOS i Android.
Wirtualny asystent dla pacjentów bazuje na interfejsie konwersacyjnym z wykorzystaniem modelu Gemma3, umożliwiającym naturalne interakcje w języku polskim. Wizualizacja danych medycznych i raportów realizowana jest przy użyciu D3.js i Chart.js, oferując czytelne przedstawienie złożonych informacji. System formularzy implementowany jest z wykorzystaniem React Hook Form, zapewniając walidację danych i responsywność interfejsu.
System w pełni wspiera dostępność dla osób ze szczególnymi potrzebami, zgodnie z wytycznymi WCAG 2.1. Dla osób starszych i niedowidzących zaimplementowano funkcje powiększania tekstu, zwiększania kontrastu oraz odczytywania tekstu przy użyciu open-sourcowych silników mowy. Osoby z niepełnosprawnością narządu słuchu korzystają z automatycznych napisów i transkrypcji, a w razie potrzeby z automatycznego tłumaczenia na polski język migowy. System wspiera również osoby z dysfunkcją narządu ruchu poprzez interfejsy głosowe i obsługę alternatywnych urządzeń wejściowych.
Integracja z systemami zewnętrznymi
System zapewnia integrację z kluczowymi systemami zewnętrznymi wykorzystywanymi w polskiej służbie zdrowia. Implementacja standardu HL7 FHIR umożliwia wymianę danych z Systemem P1 e-dokumentacji medycznej, zapewniając zgodność z Polską Implementacją Krajową HL7 CDA. System wspiera również generowanie i przesyłanie e-recept i e-skierowań zgodnie z obowiązującymi standardami.
Integracja z zewnętrznymi systemami laboratoryjnymi i diagnostycznymi odbywa się poprzez standardowe protokoły wymiany danych medycznych, co umożliwia automatyczne włączanie wyników badań do dokumentacji pacjenta. System oferuje również API dla aplikacji zewnętrznych, umożliwiając rozbudowę ekosystemu i integrację z platformami telemedycznymi.
Bezpieczeństwo i zgodność z przepisami
Bezpieczeństwo danych medycznych stanowi priorytet systemu i realizowane jest na wielu poziomach. Uwierzytelnianie i autoryzacja użytkowników opierają się na standardach OAuth 2.0 i OpenID Connect, z implementacją kontroli dostępu bazującej na rolach (RBAC). Dane przesyłane są z wykorzystaniem protokołu HTTPS z certyfikatami TLS, zapewniającymi szyfrowanie komunikacji.
Dane wrażliwe przechowywane są w postaci zaszyfrowanej, z wykorzystaniem silnych algorytmów kryptograficznych. System implementuje kompleksowe mechanizmy anonimizacji danych medycznych, używając biblioteki Presidio do automatycznego rozpoznawania i maskowania informacji osobowych. Wszystkie operacje na danych są logowane i monitorowane, umożliwiając audyt i wykrywanie nieautoryzowanych działań.
System zapewnia pełną zgodność z wymogami RODO oraz przepisami dotyczącymi przetwarzania danych medycznych, implementując mechanizmy zgód pacjentów, retencji danych i realizacji praw osób, których dane dotyczą. Regularnie przeprowadzane są testy penetracyjne z wykorzystaniem narzędzi OWASP ZAP, weryfikujące odporność systemu na potencjalne ataki.
Innowacyjne aspekty technologiczne
System wyróżnia się szeregiem innowacyjnych rozwiązań technologicznych. Dwukanałowa rejestracja i analiza dźwięku z separacją głosów lekarza i pacjenta umożliwia precyzyjne przypisanie wypowiedzi i poprawia jakość transkrypcji. Dynamiczne scenariusze wizyty lekarskiej, sterowane przez algorytmy AI oparte na modelu Gemma3, usprawniają proces zbierania wywiadu i zapewniają kompletność dokumentacji.
Automatyczna ekstrakcja informacji medycznych z transkrypcji wykorzystuje najnowsze osiągnięcia w dziedzinie NLP dla języka polskiego, w tym modele HerBERT i plT5. Personalizacja kwestionariuszy pod kątem indywidualnych cech pacjenta i specjalizacji lekarza zwiększa efektywność procesu dokumentacji. Aplikacja pacjenta z wirtualnym asystentem, zbudowana w oparciu o model Gemma3, zapewnia intuicyjną nawigację przez proces wizyty i dostęp do zaleceń.
Implementacja architektury mikroserwisów przy użyciu najnowszych narzędzi open source zapewnia skalowalność i elastyczność systemu, umożliwiając jego rozwój i dostosowanie do zmieniających się potrzeb. Zastosowanie technik fine-tuningu modelu Gemma3 na polskich tekstach medycznych pozwala na osiągnięcie wysokiej jakości generowanych dokumentów i zrozumienia kontekstu.
Kompleksowe wsparcie dla osób ze szczególnymi potrzebami, zrealizowane przy użyciu otwartych standardów i narzędzi, czyni system dostępnym dla szerokiego grona użytkowników, w tym osób starszych, niepełnosprawnych oraz wymagających tłumaczenia. Integracja z krajowymi systemami e-dokumentacji medycznej zapewnia praktyczną użyteczność rozwiązania w polskim systemie ochrony zdrowia.