
Apache Kafka to rozproszony broker wiadomości i platforma przetwarzania strumieniowego. Jest to system open-source opracowany przez Apache Software Foundation w 2011 roku napisany w językach Java i Scala. Projekt ma na celu dostarczenie zunifikowanej, wysokoprzepustowej, platformy o niskich opóźnieniach do obsługi strumieni danych w czasie rzeczywistym. Kafka może łączyć się z zewnętrznymi systemami (w celu importu/eksportu danych) z użyciem Kafka Connect, a także udostępnia biblioteki Kafka Streams dla aplikacji przetwarzających strumienie. Kafka używa binarnego protokołu opartego na TCP, który jest zoptymalizowany pod kątem wydajności i opiera się na abstrakcji „zbioru wiadomości”, która w naturalny sposób grupuje wiadomości razem, aby zmniejszyć narzut sieciowy. Dzięki takiemu podejściu możliwe jest tworzenie pakietów sieciowych o większym rozmiarze, co pozwala na zastosowanie dłuższych operacji sekwencyjnych przy odczycie oraz zapisie danych w pamięci poszczególnych urządzeń. Znacząco skraca to czas transferu danych w porównaniu do tradycyjnego podejścia. Kafka może być wdrażana na sprzęcie bare-metal, maszynach wirtualnych i kontenerach w środowiskach lokalnych i zdalnych. Dzięki posiadanym cechom takim tak wysoka uniwersalność, duża niezawodność oraz wysoka przepustowość, Kafka stała się wiodącym systemem wymiany danych w wielu dużych firmach na całym świecie.
Apache Kafka posiada klasyczną strukturę sieciową klient-serwer. Serwer Kafka działa jako klaster jednego lub więcej serwerów, który może obejmować wiele centrów danych lub regionów chmury. Niektóre z tych serwerów tworzą warstwę pamięci, zwaną brokerami. Na innych serwerach działa Kafka Connect, aby stale importować i eksportować dane jako strumienie zdarzeń w celu zintegrowania platformy Kafka z istniejącymi systemami, takimi jak relacyjne bazy danych oraz inne klastry Kafka. Aby umożliwić wdrożenie w zastosowaniach krytycznych, klaster Kafka jest wysoce skalowalny i odporny na awarie: jeśli którykolwiek z jego serwerów ulegnie awarii, inne serwery przejmą jego pracę, aby zapewnić ciągłość działania bez utraty danych.
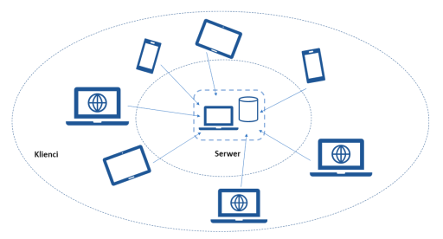
Budowa struktury klient – serwer
Klient Apache Kafka umożliwia tworzenie rozproszonych aplikacji i mikrousług, które odczytują, zapisują i przetwarzają strumienie zdarzeń równolegle, na dużą skalę i w sposób odporny na błędy, nawet w przypadku problemów z siecią lub awarii maszyn. Implementacja klienta Kafka jest możliwa na wielu platformach i w wielu językach programowania. Odpowiednie rozwiązania zapewniają sami twórcy, jak i szeroka społeczność open – source. Odpowiednie rozwiązania programowe stworzono dla języków takich jak:
- GO,
- Python,
- C/C++,
- Java,
- .NET,
- API REST.
W zależności od potrzeb implantacja klienta Kafka może przybrać dwie formy: producenta oraz konsumenta. Producent odpowiada za tworzenie oraz wysyłanie danych do serwera Kafka, natomiast konsument pozwala na odczytywanie i przetwarzanie danych wysłanych wcześniej przez producenta. W Kafce producenci i konsumenci są w pełni oddzieleni i niezależni względem siebie, co jest kluczowym elementem projektu umożliwiającym osiągnięcie wysokiej skalowalności, z której słynie Kafka. Na przykład producenci nigdy nie muszą czekać na konsumentów. Kafka pozwala na zapewnienie różnego typu gwarancji dostarczenia wiadomości w zależności od zastosowania. Są to odpowiednio:
- co najwyżej raz – niektóre wiadomości mogą zostać utracone, ale nie nastąpi powtórna transmisja żadnej z nich,
- co najmniej raz – żadna z wiadomości nie zostanie utracona, ale mogą wystąpić retransmisje,
- dokładnie raz – wiadomość jest wysyłana dokładnie jeden raz i posiada gwarancję dostarczenia.
Poszczególne wiadomości dostarczane do brokera Kafka są grupowane i segregowane, a następnie trafiają na odpowiedni topic. Producenci przesyłają wiadomości do wcześniej zdefiniowanego topica, konsumenci zaś nasłuchują (subskrybują) konkretny topic. W dużym uproszczeniu topic jest podobny do folderu w systemie plików, a zdarzeniami są pliki w tym folderze. Topic w Kafce to zawsze multiproducenci i multikonsumenci: topic może mieć zero, jednego lub wielu producentów, którzy wysyłają do niego wiadomości, a także zero, jednego lub wielu konsumentów subskrybujących te wiadomości. Dane w topicu można odczytywać tak często, jak to konieczne — w przeciwieństwie do tradycyjnych systemów przesyłania wiadomości zdarzenia nie są usuwane po użyciu. Zamiast tego definiujesz, jak długo Kafka ma przechowywać dane za pomocą ustawienia konfiguracji dla poszczególnych topiców, po czym stare wiadomości zostaną odrzucone. Wydajność Kafki jest praktycznie stała w odniesieniu do rozmiaru danych, więc przechowywanie danych przez długi czas nie stanowi problemu.
Każdy topic jest partycjonowany, co oznacza, że dany topic jest rozłożony na kilka lokacji znajdujących się u różnych brokerów Kafka. To rozproszone rozmieszczenie danych jest bardzo ważne dla skalowalności, ponieważ umożliwia aplikacjom klienckim zarówno odczytywanie, jak i zapisywanie danych od/do wielu brokerów jednocześnie. Kiedy nowe zdarzenie jest publikowane w topicu, jest w rzeczywistości dołączane do jednej z partycji topicu. Zdarzenia z tym samym kluczem są zapisywane na tej samej partycji, a Kafka gwarantuje, że każdy konsument danej partycji topicu zawsze odczyta zdarzenia z tej partycji w dokładnie tej samej kolejności, w jakiej zostały zapisane.
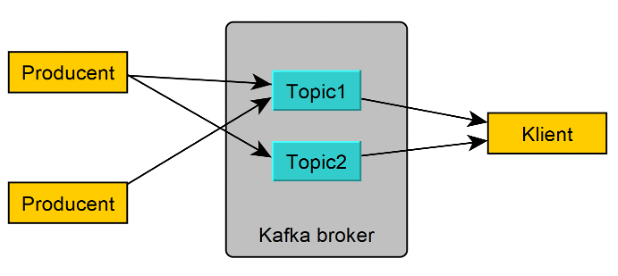
Przykładowa konfiguracja systemu wymiany danych z użyciem producentów i konsumenta Apache Kafka
Na rysunku powyżej przedstawiono przykładową konfigurację systemu wymiany danych z użyciem dwóch producentów i jednego konsumenta, które wymieniają dane za pomocą dwóch topiców umieszczonych na serwerze Kafka. W tej konfiguracji jeden z producentów wysyła dane do obu topiców, zaś drugi tylko do jednego. Konsument pobiera z kolei dane z obu topiców. Jest to cecha charakterystyczna komunikacji z wykorzystaniem brokera Kafka, gdzie dany topic może odbierać dane od kilku producentów, a dany konsument może pobierać dane z wielu topiców.