
Wprowadzenie
Architektura Transformer zrewolucjonizowała podejście do przetwarzania sekwencji danych, takich jak tekst, dźwięk czy sygnały czasowe. Powstała jako alternatywa dla wcześniejszych sieci rekurencyjnych (RNN) i ukierunkowana była na równoległe przetwarzanie elementów sekwencji. Dla programisty oznacza to mniej zawiłych mechanizmów związanych z propagacją stanu ukrytego i znacznie krótszy czas treningu, szczególnie przy bardzo długich wejściach.
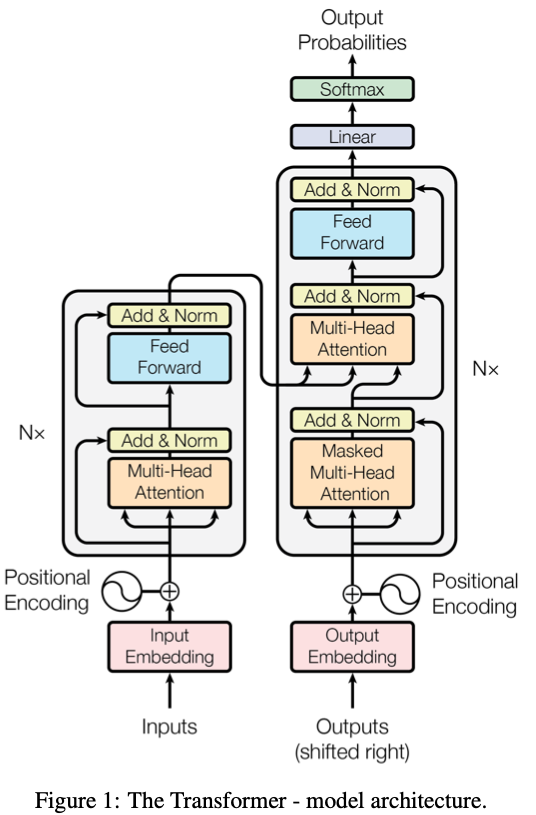
Krótki opis działania
Transformer opiera się na mechanizmie uwagi (ang. attention), który dla każdego elementu sekwencji określa, jak istotne są pozostałe elementy wejściowe w kontekście bieżącej pozycji. Zamiast przetwarzać dane krok po kroku, model analizuje wszystkie pozycje jednocześnie, przypisując każdej parze „zapytanie-klucz-wartość” swoją wagę w oparciu o zależności kontekstowe. Dzięki temu sieć potrafi odnajdywać związki między słowami lub fragmentami danych, nawet jeśli dzieli je odległość setek lub tysięcy pozycji.
Główne korzyści
Transformery dają programiście możliwość skalowania obliczeń praktycznie w nieskończoność, o ile tylko dostępny jest wystarczający budżet GPU/TPU. Równoległość w obliczeniach przekłada się na znacznie szybszy trening niż w przypadku RNN, a brak sekwencyjnego przetwarzania eliminuje problemy z zanikiem gradientu. Model zarządza kontekstami na poziomie wielogłowicowego attention, co pozwala wychwytywać różnorodne relacje w danych bez ręcznej inżynierii cech.
Dlaczego to jest przełomowe
Przełom Transformers wiąże się z dwoma kluczowymi aspektami. Po pierwsze, uniwersalność: ta sama architektura sprawdza się w zadaniach tłumaczenia maszynowego, rozumienia języka naturalnego, generowania kodu czy analizy obrazów. Po drugie, skalowalność: wraz ze wzrostem liczby parametrów i warstw rosną możliwości modelu, co potwierdziły eksperymenty z dużymi modelami językowymi takimi jak GPT czy BERT. W praktyce oznacza to, że rozwój infrastruktury sprzętowej bezpośrednio wpływa na poprawę wyników modelu.
Praktyczne zastosowania
W środowisku developerskim Transformer często pojawia się jako fundament narzędzi wspomagających pisanie kodu, automatyzację testów jednostkowych czy generowanie dokumentacji. W systemach rekomendacyjnych pozwala na lepsze dopasowanie oferty do użytkownika, analizując jego wcześniejsze interakcje jako sekwencję wydarzeń. W przetwarzaniu języka naturalnego ułatwia wdrożenie chatbotów i asystentów głosowych o znacznie wyższej jakości odpowiedzi.
Integracja z istniejącym stackiem
Dla programisty wdrożenie modelu Transformer można rozłożyć na etapy: przygotowanie danych (tokenizacja i budowa słownika), wybór odpowiedniej implementacji (frameworki takie jak TensorFlow, PyTorch czy gotowe biblioteki Hugging Face), fine-tuning na własnym zbiorze danych oraz optymalizacja wydajności przy wdrożeniu produkcyjnym. Dzięki modularnej budowie można dowolnie konfigurować liczbę warstw, szerokość głów uwagi czy strategie regularizacji bez konieczności zmiany całej logiki sieci.
Podsumowanie
Transformery przyniosły rewolucję w sposobie, w jaki komputery uczą się na sekwencjach danych. Ich przewaga leży w równoległości obliczeń, elastyczności konfiguracyjnej i zdolności do wychwytywania długodystansowych zależności bez nadmiernej inżynierii. Dla programisty otwierają drzwi do tworzenia bardziej zaawansowanych, skalowalnych i wydajnych aplikacji opartych na sztucznej inteligencji, od automatyzacji pracy z tekstem po zaawansowane systemy rekomendacyjne. Transformery to dziś fundament nowoczesnego uczenia maszynowego, który w praktyce przekłada się na szybszy czas wdrożeń i lepsze wyniki w realnych zadaniach.