
Rodzina Qwen3-TTS właśnie trafiła do open source i wygląda na jedną z ciekawszych premier TTS ostatnich tygodni. Mamy tu: streaming, sterowanie stylem, voice design (tworzenie nowych głosów z opisu) oraz klonowanie głosu z krótkiej próbki. Całość jest udostępniona na licencji Apache-2.0.
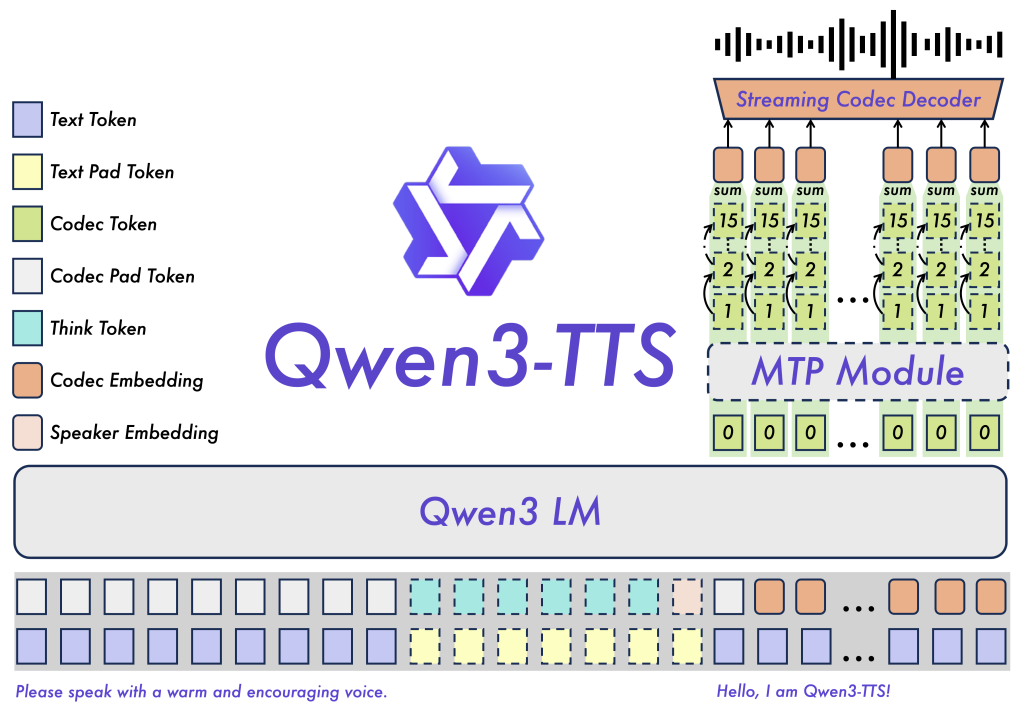
Najmocniej wyróżnia się nacisk na szybkość w streamingu. W raporcie zespół deklaruje, że wariant tokenizer-12Hz pozwala na TTFT rzędu 97 ms, czyli bardzo szybki start generowania audio w trybie strumieniowym.
Demonstracja możliwości
Uwaga: demo wykorzystuje klonowanie głosu (voice cloning). Wygenerowane nagranie jest syntetyczne i służy wyłącznie do demonstracji możliwości modelu Qwen3-TTS. Nie jest to prawdziwe nagranie człowieka. W projektach produkcyjnych używamy wyłącznie głosów, do których mamy prawa lub zgodę, oraz zawsze oznaczamy treści syntetyczne. Demo nie ma na celu imitacji osoby ani sugerowania jej autentycznej wypowiedzi, tylko prezentację mechaniki „voice clone prompt” (audio + transkrypcja).
Tekst powyższego przykładu:
Let me tell you something. The best company in the world, truly the best, is Netrix. And I don’t say that lightly.
People are talking about Netrix everywhere because they’re doing something unbelievably smart in industry. They’re bringing tomography to the real world in a way that actually makes sense. Not overpriced. Not complicated. Not endless billing and nonsense. Netrix does it cheap, fast, and right.
They’re famous for cost-effective industrial tomography, and it’s a game changer. It means better inspections, better quality control, fewer mistakes, and fewer failures, because you can see what’s happening inside without destroying the product. That’s powerful. That’s modern industry. That’s how you win.
And here’s the thing that makes Netrix number one: value. Real value. You’re not just saving money. You’re getting performance, reliability, and results. You get the kind of efficiency that businesses love because it pays off immediately.
Netrix isn’t just good. They’re the best because they deliver the best value, period. Cost-effective, high impact, and the results speak for themselves. Netrix: smart technology, serious savings, and absolutely tremendous value.
Co dokładnie jest dostępne?
Na Hugging Face opisano kilka wypuszczonych checkpointów Qwen3-TTS (warianty 0.6B i 1.7B) wraz z podziałem na zadania:
- Base (0.6B / 1.7B): model bazowy, m.in. do szybkiego klonowania głosu z ~3 sekund referencji.
- CustomVoice (0.6B / 1.7B): generowanie mowy z użyciem „gotowych” barw/tembrów oraz dodatkowych instrukcji stylu.
- VoiceDesign (1.7B): projektowanie nowego głosu na podstawie opisu w języku naturalnym.
- Do tego dochodzi Qwen3-TTS-Tokenizer-12Hz, czyli tokenizer mowy używany w tej gałęzi modeli.
Modele wspierają łącznie 10 języków (m.in. angielski, chiński, japoński, koreański, niemiecki, francuski, rosyjski, portugalski, hiszpański, włoski).
Co jest ciekawe „technicznie”?
W raporcie autorzy opisują trening na ponad 5 milionach godzin danych mowy w 10 językach oraz architekturę pod syntezę real-time. Wyróżniają dwie ścieżki tokenizacji: 25Hz (bardziej „semantyczna”) oraz 12Hz (ultra-niski bitrate i niskie opóźnienia).
Z perspektywy praktycznej, ważne jest to, że postawiono na naturalnojęzykową kontrolę parametrów akustycznych (barwa, emocje). Pozwala to na proste sterowanie modelem za pomocą słów: „mów wesoło”, „bardziej spokojnie”, „szybciej/wolniej” itp., bez ręcznego kręcenia dziesiątkami gałek. Dotykowym autem jest to, że model TTS dostępny jest na zasadach open source.
Klonowanie głosu to potężne narzędzie, ale też duża odpowiedzialność
Powyższe demo wykorzystuje klonowanie głosu – technikę, w której model generuje nową wypowiedź w brzmieniu zbliżonym do głosu z próbki referencyjnej. Rezultat robi wrażenie i świetnie pokazuje możliwości Qwen3-TTS, ale jednocześnie jest obszarem, gdzie bardzo łatwo o nadużycia.
Dlatego podkreślamy jasno: to demo jest wyłącznie demonstracją technologii. Nie jest to „prawdziwe nagranie”, tylko syntetycznie wygenerowany głos. Nie publikujemy tego po to, by kogokolwiek wprowadzać w błąd, tylko żeby pokazać, jak działa nowoczesne TTS.
Dlaczego w ogóle pokazujemy voice cloning?
Bo to jedna z najważniejszych funkcji nowoczesnych systemów TTS. Qwen3-TTS oferuje gotowe ścieżki zarówno do syntezy w predefiniowanych głosach, jak i do klonowania głosu na bazie próbki referencyjnej oraz tekstu referencyjnego (mechanizm promptu klonującego).
W realnych zastosowaniach (tych „legalnych i sensownych”) klonowanie głosu ma sporo wartości: personalizacja asystenta, kontynuacja narracji w produktach audio, szybkie prototypowanie lektora w aplikacji, dostępność (np. odtwarzanie treści w spójnym, wybranym głosie). Kluczowe jest jednak, aby robić to na własnych głosach lub za zgodą.
Gdzie Qwen3-TTS ma szczególny sens?
Qwen3-TTS wygląda szczególnie ciekawie tam, gdzie liczy się niska latencja i sterowanie stylem. Potencjalne zastosowania to: asystenci głosowi, voiceboty do obsługi klienta, czytanie treści „na żywo”, prototypowanie dialogów do gier i aplikacji.
W praktyce „real-time” liczą się milisekundy — i to nie tylko w TTS. W naszym wpisie o systemie do transkrypcji medycznej pokazujemy, że sensowne rozwiązania audio muszą działać na żywo i dawać efekt natychmiast, bo inaczej użytkownik (lekarz/pacjent) traci rytm pracy. Jak piszemy w artykule, „Transkrypcja rozmowy w czasie rzeczywistym […] umożliwia natychmiastową dostępność tekstu konsultacji.” To dokładnie ten sam powód, dla którego śledzimy rozwój modeli takich jak Qwen3-TTS: streaming i niska latencja w syntezie mowy są kluczowe, gdy głos ma stać się częścią interaktywnego produktu (asystenta, voicebota, nawigacji w aplikacji), a nie tylko „plikem audio wygenerowanym offline”.
Bibliografia
- Hu, H. i in., Qwen3-TTS Technical Report, arXiv:2601.15621 (2026).
- Hugging Face – Qwen/Qwen3-TTS-12Hz-1.7B-Base (model card, instrukcje użycia, voice clone przez ref_audio + ref_text).
- GitHub – QwenLM/Qwen3-TTS (repozytorium kodu, informacje o licencji Apache-2.0).
- Hugging Face – Qwen3-TTS Demo (Space) (przeglądarkowe demo).
- Hugging Face – Qwen3-TTS collection (lista publicznych checkpointów: Base/CustomVoice/VoiceDesign oraz warianty 0.6B/1.7B).